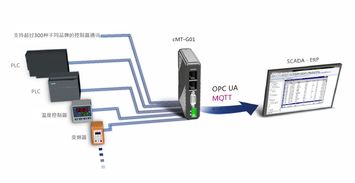
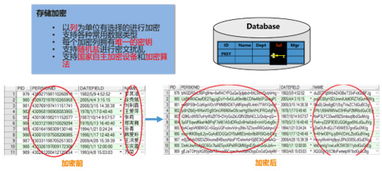
日志采集系统架构详解 数据处理与存储服务的设计与实践
在当今数据驱动的时代,日志作为系统运行状态、用户行为和安全事件的关键记录,其价值日益凸显。一个高效、可靠的日志采集系统,尤其是其数据处理与存储服务层,是挖掘日志价值、保障业务稳定与驱动智能决策的核心基础设施。本文将深入探讨日志采集系统中数据处理与存储服务的架构设计、关键技术与实践考量。
一、数据处理与存储服务的核心定位
数据处理与存储服务是日志采集流水线的“中枢大脑”,位于日志采集 Agent(如 Filebeat、Fluentd)之后,可视化与分析平台之前。它主要负责两大部分:
- 数据处理:对原始日志进行实时清洗、解析、富化、过滤、聚合与转换,将其从非结构化或半结构化文本,转化为便于分析和存储的结构化数据。
- 数据存储:提供高吞吐、低成本、可扩展的持久化存储方案,并支持高效的检索与分析查询。
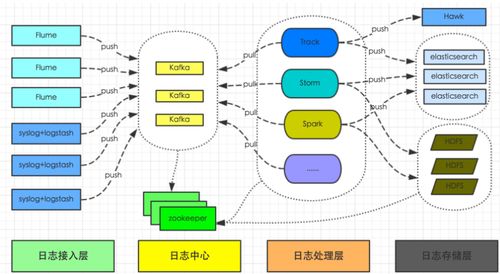
二、典型架构分层与组件
一个成熟的架构通常呈现分层解耦的特点:
1. 消息队列/流处理缓冲层
- 角色:承接采集端的海量数据流,实现生产者与消费者的解耦,提供流量削峰、缓冲和可靠传递保障。
- 技术选型:Apache Kafka、Apache Pulsar、RocketMQ。Kafka因其高吞吐、分布式和持久化特性成为主流选择。
2. 实时流处理层
- 角色:从消息队列中消费数据,进行实时的清洗、解析(如正则解析、Grok、JSON解析)、字段提取、格式标准化、敏感信息脱敏、日志分类等。
- 技术选型:Apache Flink(提供精确一次语义、复杂事件处理)、Apache Spark Streaming、或基于 Logstash 的管道。Flink在状态管理和实时计算方面优势显著。
3. 存储与索引层
- 角色:长期存储处理后的日志数据,并建立索引以支持快速检索(全文搜索、字段过滤、范围查询等)。
- 技术选型:
- 全文搜索引擎:Elasticsearch(最流行),提供近实时搜索与强大的聚合分析能力。通常与 Kibana 构成 ELK 栈。
- 时序数据库:如果日志带有强时间序列特征(如指标型日志),可选用 InfluxDB、Prometheus(更适合监控指标)或 TDengine。
- 低成本对象存储:对于需要长期归档或冷数据,可将数据转存至 S3、OSS、HDFS,结合 Elasticsearch 的“热-温-冷”架构控制成本。
4. 元数据管理与服务层
- 角色:管理日志的元信息,如日志源(Source)、模式(Schema)、解析规则、存储策略、生命周期(TTL)、权限等。可基于配置中心(如 Apollo、Nacos)或数据库实现。
三、数据处理的关键流程
- 解析与结构化:这是将原始文本转化为信息的关键。例如,使用 Grok 模式将一行 Nginx 访问日志解析出
client<em>ip、timestamp、method、url、status、response</em>time等字段。 - 数据富化:通过查询外部数据源(如CMDB、用户数据库、IP地理信息库)为日志记录添加上下文信息。例如,将 IP 地址富化为地理位置、业务部门。
- 过滤与路由:丢弃无用的调试日志或将不同类型的日志(如应用日志、访问日志、错误日志)路由到不同的 Kafka Topic 或下游存储索引中。
- 聚合与计算:在流处理中实时计算指标,如每分钟错误数、接口平均响应时间、独立访客数(UV)等,并将结果写入时序数据库供监控告警使用。
四、存储方案的设计考量
- 性能与成本平衡:采用分层存储策略。
- 热数据:近期高频查询的数据(如过去7天),存储在 SSD 支持的 Elasticsearch 集群中,保证查询速度。
- 温/冷数据:历史数据(如7天前),可转移到成本更低的机械硬盘 Elasticsearch 节点,或转储到对象存储,通过 Elasticsearch 的 ILM(索引生命周期管理)或 Catalog 服务(如 Apache Hive)进行查询。
- 可扩展性:存储系统必须能水平扩展以应对数据量的增长。Elasticsearch 通过分片(Shard)机制实现。
- 可靠性:通过副本(Replica)机制防止数据丢失。对象存储本身通常提供高耐久性。
- 查询灵活性:根据查询模式选择存储。详单式查询用 Elasticsearch;固定模式的时间范围聚合分析,可考虑物化视图或预聚合后存入 ClickHouse 等 OLAP 数据库。
五、实践建议与挑战
- 标准化与契约:推动应用日志输出标准化(如 JSON 格式),并定义清晰的日志 Schema,能极大降低后期解析的复杂度。
- 监控与治理:对整个数据处理管道(队列堆积、处理延迟、错误率)和存储集群(磁盘使用率、查询延迟、节点健康)进行全方位监控。
- 安全与合规:确保日志中的敏感信息(用户ID、手机号)在存储前已脱敏或加密,并设置严格的访问控制。
- 挑战应对:
- 数据爆炸:通过采样存储非关键日志、合理设置日志级别来控制数据量。
- 解析复杂度:对于格式多变的日志,可采用机器学习辅助的日志解析方案。
- 运维复杂性:考虑使用全托管的云服务(如阿里云 SLS、腾讯云 CLS、AWS OpenSearch)来降低自维护成本。
###
数据处理与存储服务是日志采集系统从“数据收集”迈向“价值洞察”的桥梁。一个优秀的架构需要在吞吐量、延迟、成本、可靠性和查询能力之间取得精巧的平衡。随着云原生和 Serverless 技术的发展,日志处理架构正朝着更弹性、更智能和更集成的方向演进。设计者应紧密结合自身业务规模、技术栈和团队能力,选择最合适的组件与架构模式,构建稳定高效的数据地基。
如若转载,请注明出处:http://www.lqcg88.com/product/48.html
更新时间:2026-06-19 22:34:37